Content storage and structure
Magnolia stores all content (web pages, images, documents, configuration, data) in a content repository.
The magnolia repository contains workspaces and further custom workspaces can be added.
A content repository is a high-level information management system that’s a superset of traditional data repositories. It implements content services such as:
-
Hierarchical, structured and unstructured content
-
Granular content access and access control
-
Node types, property types (text, number, date, binary)
-
Queries (XPath, SQL)
-
Import and export
-
Referential integrity
-
Versioning
-
Observation
-
Locking
-
Clustering
-
Multiple persistence models
The repository implementation chosen, Apache Jackrabbit, adheres to the Java Content Repository standard (JCR).
Hierarchical content store
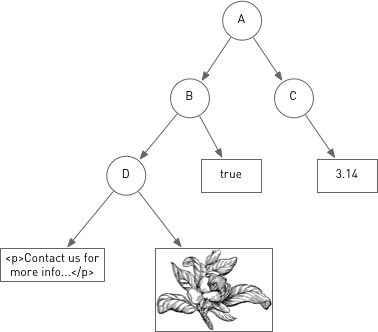
A content repository is designed to store, search and retrieve hierarchical data. Data consists of a tree of nodes with associated properties. Data is stored in the properties. They may store simple values such as numbers and strings or binary data (images, documents) of arbitrary length. Nodes may optionally have one or more types associated with them, which in turn dictates the type of their properties, the number and type of their child nodes, and certain behavioral characteristics.
In the example below, A, B, C, and D are nodes. The boxes represent properties with Boolean, numerical, string, and binary values. You don’t need to worry about how the data is stored. The repository provides a standardized way to store and retrieve it whether it resides in a traditional database or in a file system.
JCR standard API for content repositories
Java Content Repository (JCR) is a standard interface for accessing content repositories. JCR version 1.0 was specified in Java Specification Request 170 (JSR-170). Version 2.0 in JSR-283 is also final. JCR specifies a hierarchical content store with support for structured and unstructured content.
Magnolia was the first open-source content management system built specifically to leverage JCR. The standard decouples the responsibilities of content storage from content management and provides a common API that enables standardized content reuse across the enterprise and between applications. Magnolia uses the open-source Jackrabbit reference implementation.
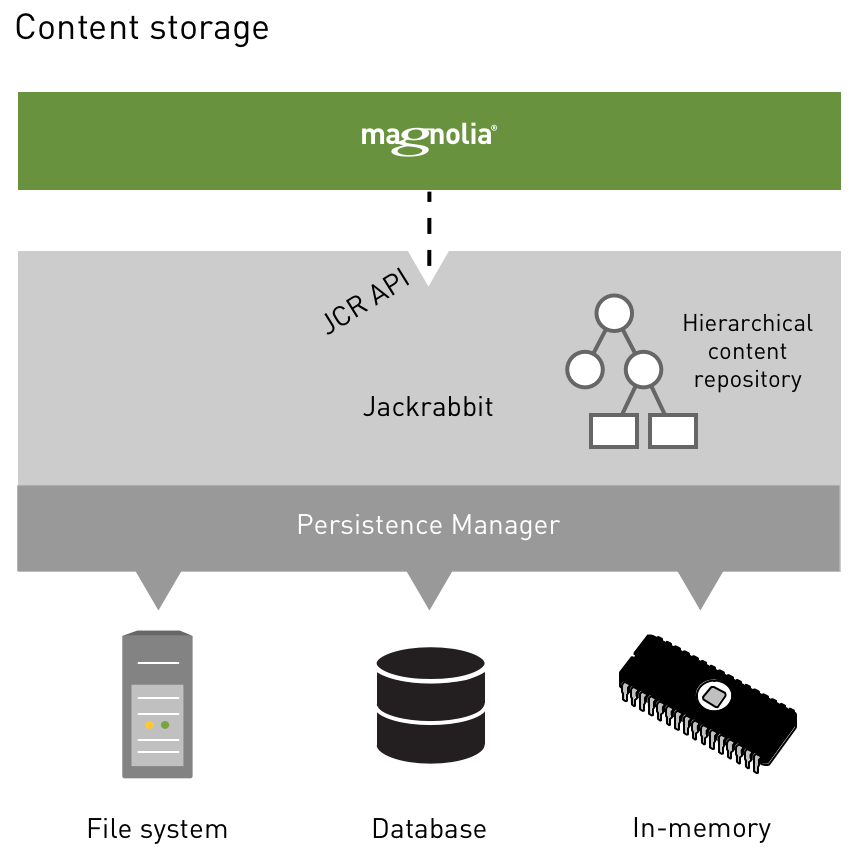
As depicted above, Magnolia typically has one repository, Magnolia.
That, in turn, contains several workspaces.
One workspace stores website content, another stores user accounts, a third stores configuration, and so on.
For more on creating custom workspaces and naming conventions, see Workspaces.
Persistent storage
A persistence manager (PM) is an internal Jackrabbit component that handles the persistent storage of content nodes and properties. Each workspace of a Jackrabbit content repository can use a separate persistence manager to store content for that workspace. The persistence manager sits at the bottom layer of the Jackrabbit system architecture. Reliability, integrity and performance of the PM are crucial to the overall stability and performance of the repository.
In order to avoid integrity issues and to benefit from services such as observation, clustering and indexing, you should always access the content through the JCR API. Changing the data directly (bypassing the API) causes serious issues. This may sound restrictive but the API is actually quite versatile. You can even access the content repository from external applications using the API.
The choice of persistence managers includes:
-
Database: Magnolia uses a database as persistence manager by default. This is the most common option. We ship WAR files and operating system specific bundles with the H2 database. H2 is an embedded database that allows us to package a fully operational Magnolia example into a single download, including configuration details and demonstration websites. It requires minimal installation effort from users. However, for production environments, we recommend an enterprise-scale database such as MySQL, PostgreSQL or Oracle. All of them work with JCR. Database connections are based on JDBC, involve zero deployment, and run fast.
The MySQL InnoDB storage engine is supported by Magnolia, the MyISAM engine isn’t. InnoDB is the default engine in MySQL 5.5or later. -
File system: This kind of data store is typically not meant to run in production environments, except in read-only cases, but it can be very fast.
-
In-memory: This is a great persistence manager for testing and for small workspaces. All content is kept in memory and lost as soon as the repository is closed. Even faster than a file system. Again, not for production use.
Magnolia DX Core allows you to switch between persistence managers.
Each workspace has a workspace.xml file in which its persistence manager is configured.
|
To avoid losing content, you must create a verifiable content migration before switching persistence managers. Content migration is a time-consuming process. You can use SQL dumps, but you need to review them carefully to ensure they have the proper configurations to import to the target data store. |
Changing the PersistenceManager entry in the XML allows you to switch persistence managers to use the class best suited for your use case.
For more, see classes, and check out the Apache PersistenceManagerFAQ if needed.
|
Use native database tools to generate and restore backups using a verifiable content migration plan. Logical backups are a great option to copy the database to another environment. For more, see Backing up and restoring instances. The Nodes API allows you to use a REST service for CRUD operations against a running Magnolia instance. Alternatively, you can import content via bootstrapping. Whichever migration approach you choose, ensure the content migration process is verifiable and planned. |
|
If you removed the persistence volume for a Magnolia instance or started Magnolia in a new environment using an existing database, you must delete the search index and restart it for the index to build successfully. To remove the index, run the following from your affected environment. |